Module 1.4: DNA, Genomes, Whole Genome Sequencing, Mutations, and Genome Evolution
Introduction to Module 1.4
Welcome! In Module 1.4, we will talk about V. cholerae genomes: what is DNA, what is a genome, what is genome sequencing, and how genomes evolve by mutations. This module may take you roughly one hour to work through (maybe a bit more or less than that, depending on your own pace). While we will explain terms as we go along, we have also included a glossary of key terms for Module 1.
The V. cholerae Genome and Whole-Genome Sequencing (WGS) of V. cholerae
Just as for us humans, the genetic material of V. cholerae consists of DNA. The DNA of V. cholerae contains all the genetic instructions specifying the development of a V. cholerae cell.
You may be already familiar with the structure of DNA, a famous molecule with a double helix structure. DNA molecules consist of two chains (also known as ‘strands’) of smaller molecules called ‘nucleotides’ (Figure 18). Each nucleotide consists of three parts: a sugar called deoxyribose, a phosphate group, and one of four ‘bases’. The bases are thymine (abbreviated as ‘T’), adenine (‘A’), guanine (‘G’) and cytosine (‘C’).

Figure 18. Structure of DNA with sugar phosphate backbone and bases. The sugars and phosphates form the backbone of the double helix. Image attribution: this image by National Human Genome Research Institute is in the Public Domain. / Adapted by Avril Coghlan from the original to indicate the 5’ and 3’ ends of each DNA strand.
{kind=link}
The bases in the two strands of a DNA double helix are ‘complementary’ to each other: that is, T pairs with A and G pairs with C. Thus, if one strand has the sequence of bases AGTACG, the other strand must have the sequence of bases TCATGC (Figure 18). For convenience, one strand in a DNA double helix is called the ‘forward’ or ‘+’ (‘plus’) strand, and the other strand the ‘reverse’ or ‘-’ (‘minus’) strand.
Each strand of DNA also has a direction. That is, each strand has a 5’ end and a 3’ end (said ‘5-prime’ and ‘3-prime’), where the 5’ end is the end with a terminal phosphate group (Figure 18). In a DNA double helix, the two strands have opposite directions. By convention, we write a DNA sequence as the sequence of bases from 5’ to 3’ on the + strand. If the + strand sequence is 5’-AGTACG-3’, it’s just written TCATGC (Figure 18).
The ‘genome’ of V. cholerae is the name we give to the set of all DNA molecules in a V. cholerae cell. In each cell, the V. cholerae genome is organised into two circular ‘chromosomes’, each consisting of a long circular DNA molecule (Figure 19). In total the two circular chromosomes contain about 4 million base-pairs (4 Mb), where Chromosome 1 is about 3 Mb and Chromosome 2 about 1 million base-pairs (1 Mb; Heidelberg et al 2000).

Figure 19. A circular representation of the two chromosomes of O1 El Tor V. cholerae N16961 genome. This shows the two circular chromosomes of V. cholerae, for a typical 7PET isolate, isolate N16961. The outside circles in blue represent protein-coding genes on the forward and reverse strand of the DNA. Between them, the two chromosomes of V. cholerae include almost 4000 genes in a typical 7PET isolate from the 7PET lineage. Other key features of the chromosomes are highlighted as green boxes, where the green box labelled ‘5’ is the ‘CTX prophage region’ that contains several genes, including ctxA and ctxB, which encode the A and B subunits of the cholera toxin, respectively. Image attribution: this image by Mutreja & Dougan 2020 is licensed under CC BY 4.0. / Adapted by Avril Coghlan from the original to hide additional details that were not the focus here.
When we talk about ‘sequencing the genome’ of an organism, we mean figuring out the sequence of bases on the strands of its DNA molecules. Later in this course we will talk about different methods for sequencing DNA.
The first time that a V. cholerae isolate’s genome was fully sequenced was in the year 2000, for a V. cholerae 7PET laboratory strain called N16961 that was originally isolated in Bangladesh (Heidelberg et al 2000). Since the year 2000, the genomes of thousands of other V. cholerae isolates have been sequenced. There are quite a lot of small differences between different V. cholerae isolates’ genomes (that is, there is genetic variation within V. cholerae), but the majority of V. cholerae isolates have two circular chromosomes that together contain about 4 Mb of DNA.
Genes of V. cholerae
Each of the two chromosomes of V. cholerae includes many hundred of genes. Each gene comprises a segment of its DNA, typically hundreds or thousands of base-pairs in length. A very common type of gene is a protein-coding gene, which is a stretch of DNA which encodes (specifies the production of) a particular protein. For example, ctxA and ctxB are two V. cholerae genes that encode the CtxA and CtxB proteins, the two proteins that form cholera toxin. In total the two V. cholerae chromosomes contain almost 4000 protein-coding genes in a typical isolate from the 7PET lineage (Heidelberg et al 2000).
The ctxA and ctxB genes are usually found close together in the V. cholerae genome, in a region known as the CTX prophage region that also includes some other genes (Figure 20). Practically 100% of 7PET isolates contain the CTX prophage region in their chromosome, and so produce cholera toxin, and therefore cause a human host to suffer acute watery diarrhoea. Isolates of a small number of non-epidemic lineages of V. cholerae, most of which are relatively closely related to 7PET (e.g. L3, L9, Gulf Coast, Classical), sometimes have ctxA and ctxB genes (Chun et al 2009, Hao et al 2023; Domman et al 2017; see Figure 13 above). Occasionally ctxAB genes are seen in isolates of non-epidemic lineages of V. cholerae that are very distantly related to 7PET, but this is very rare (e.g. isolate V51 described in Chun et al 2009).

Figure 20. A diagram showing the CTX prophage region of Chromosome 1 of 7PET laboratory strain N16961. The blue arrows represent genes. The ctxA and ctxB genes encode the A and B subunits, respectively, of the cholera toxin protein complex. Image attribution: this image by Avril Coghlan is licensed under CC BY 4.0. The information on the genes’ order and names was taken from Pant et al 2020.
How Do Lineages Emerge at the Genetic Level?
Like other bacteria, V. cholerae populations reproduce by cell division, with the DNA (genetic material) of descendant cells being identical to the DNA of the parent cells. Isolates that descended recently from the same ancestral cell and are identical (or nearly identical) genetically are said to belong to the same clone, or be clonal.
Mutations (changes) in the DNA, are a source of genetic variation in V. cholerae; these sometimes occur when DNA is being copied during cell division, but can also occur due to DNA damage, for example damage due to ultraviolet (UV) radiation or mutagenic (mutation-inducing) chemicals such as tobacco products.
Over evolutionary time, different clones of a bacterial species independently accumulate mutations, so they eventually they become so different at the genetic level that we can consider them different lineages of the species (Figure 5). That is, a lineage is group of organisms belonging to the same bacterial species, and that are genetically more closely related to each other than other members of the same species (adapted from a definition by the National Cancer Institute). There can be many lineages within a particular bacterial species. The bacteria belonging to one particular lineage are all relatively clonal (highly similar at the genetic level); they all descended from a relatively recent common ancestor (although ‘recent’ in evolutionary time may be hundreds or thousands of years ago!); and they usually present similar biological features, such as a specific pattern of virulence (Bacigalupe 2017). Note that the word ‘strain’ is sometimes used interchangeably with ‘lineage’, but we prefer here to use the term ‘lineage’ because ‘strain’ is also commonly used to refer to a single bacterial isolate that has been cultured over time in a laboratory.
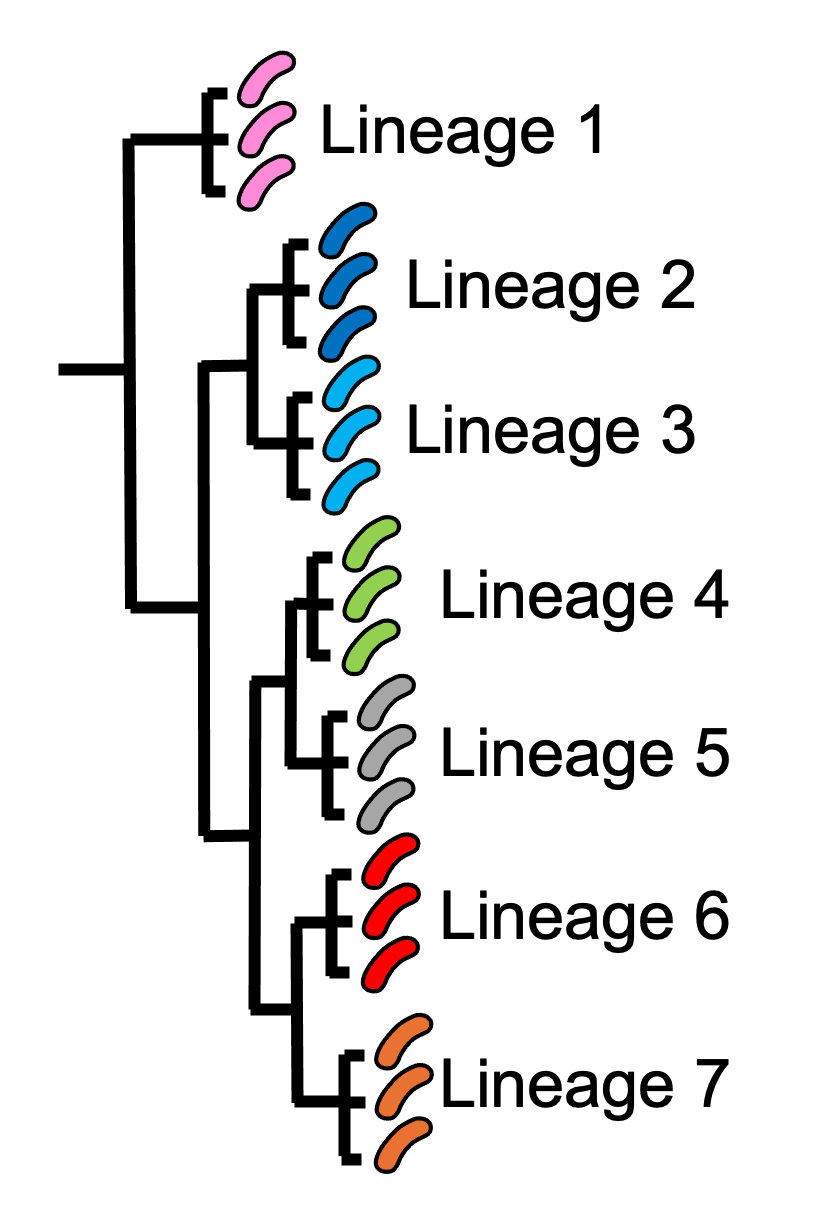
Figure 5. The population structure of a bacterial species can contain genetically distinguishable lineages. The isolates that belong to the same lineage are much closer to each other genetically, and share a more recent common ancestor with each other, compared to isolates of different lineages. This cartoon shows a ‘phylogenetic tree’ representing the evolution of seven different lineages of the same bacterial species (similar to a family tree). For illustrative purposes, we show three isolates of each lineage, and represent the isolates by pink, dark blue, light blue, green, grey, red and orange V. cholerae images, respectively. Isolates of the red lineage are high similar genetically so are considered to belong to the same lineage (lineage 6). Similarly, isolates of the orange lineage are highly similar genetically to each other, but are relatively distant from lineage 6, so are considered to belong to a separate lineage (lineage 7). Image attribution: this image by Avril Coghlan is licensed under CC BY 4.0.

Watch a talk by Dr Nick Thomson, a researcher in cholera genomics at the Wellcome Sanger Institute, UK, on “Understanding Health and Disease at a Global Scale” (14 minutes).
Watch a talk by Dr François-Xavier Weill, a leading cholera researcher based in the Pasteur Institute, Paris, on his work on genomics for tracing the cholera epidemic in Africa (26 minutes).
Brief Summary
The key take-home messages of this chapter are:
Cholera, a disease characterised by acute watery diarrhoea, is caused by ingestion of Vibrio cholerae
Cholera toxin is the most important virulence factor of V. cholerae; cholera toxin triggers acute watery diarrhoea
V. cholerae is distributed globally, and is a very diverse species with many different lineages
At present there is only one lineage that causes pandemic/epidemic cholera: 7PET, an extremely infectious and virulent lineage
The genome of a typical 7PET isolate has 4 million base-pairs (4 Mb) of DNA, and contains about 4000 genes
Practically all 7PET isolates have the genes that encode cholera toxin (genes ctxA and ctxB)
A 7PET outbreak requires a rapid and large public health response to halt/reduce it, e.g. WASH, treatment centres, vaccination
Whole genome sequencing (WGS) can be used to determine whether a new outbreak of diarrhoeal illness is caused by 7PET
Vibriowatch
In later modules of this course, you will learn how to carry out bioinformatics analyses using Vibriowatch, as well as other bioinformatics tools. If you already have cholera genomic data to analyse, and want to get going quickly, you may also be interested in our Vibriowatch tutorial.
Contact
I will be grateful if you will send me (Avril Coghlan) corrections or suggestions for improvements to my email address alc@sanger.ac.uk
Acknowledgements
Contributors to this course: Avril Coghlan, Matt Dorman, Ismail Bashir, Anne Bishop, Amber Barton, Stephanie McGimpsey, Jolynne Mokaya, Nisha Singh, Nick Thomson.